Medidas de Tendencia Central
Al describir grupos de observaciones, con frecuencia es conveniente resumir la información con un solo número. Este número que, para tal fin, suele situarse hacia el centro de la distribución de datos se denomina medida o parámetro de tendencia central o de centralización.
Las medidas de tendencia central corresponden a valores que generalmente se ubican en la parte central de un conjunto de datos. (Ellas permiten analizar los datos en torno a un valor central). Entre éstas están la media aritmética, la moda y la mediana.
La Media Aritmética
Conocida como promedio, es la suma de todos los datos divididos entre el número de ellos.
Definición formal
Dado un conjunto numérico de datos, x1, x2, ..., xn, se define su media aritmética como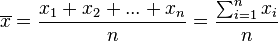
Moda
La moda es el dato más repetido, el valor de la variable con mayor frecuencia Absoluta.
Su cálculo es extremadamente sencillo, pues sólo necesita un recuento. En variables continuas, expresadas en intervalos, existe el denominado intervalo modal o, en su defecto, si es necesario obtener un valor concreto de la variable.
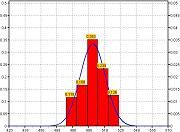
Por ejemplo, el número de personas en distintos vehículos en una carretera: 5-7-4-6-9-5-6-1-5-3-7. El número que más se repite es 5, entonces la moda es 5.Hablaremos de una distribución bimodal de los datos, cuando encontremos dos modas, es decir, dos datos que tengan la misma frecuencia absoluta máxima. Cuando en una distribución de datos se encuentran tres o más modas, entonces es multimodal. Por último, si todas las variables tienen la misma frecuencia diremos que no hay moda.Cuando tratamos con datos agrupados en intervalos, antes de calcular la moda, se ha de definir el intervalo modal. El intervalo modal es el de mayor frecuencia absoluta.La moda, cuando los datos están agrupados, es un punto que divide el intervalo modal en dos partes de la forma p y c-p, siendo c la amplitud del intervalo, que verifiquen que: Siendo
Siendo  la frecuencia absoluta del intervalo modal y
la frecuencia absoluta del intervalo modal y 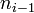 y
y 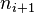 las frecuencias absolutas de los intervalos anterior y posterior, respectivamente, alLas calificaciones en la asignatura de Matemáticas de 39 alumnos de una clase viene dada por la siguiente tabla (debajo):
las frecuencias absolutas de los intervalos anterior y posterior, respectivamente, alLas calificaciones en la asignatura de Matemáticas de 39 alumnos de una clase viene dada por la siguiente tabla (debajo):| Calificaciones | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| Número de alumnos | 2 | 2 | 4 | 5 | 8 | 9 | 3 | 4 | 2 |
Mediana
La mediana es un valor de la variable que deja por debajo de sí a la mitad de los datos, una vez que éstos están ordenados de menor a mayor.7 Por ejemplo, la mediana del número de hijos de un conjunto de trece familias, cuyos respectivos hijos son: 3, 4, 2, 3, 2, 1, 1, 2, 1, 1, 2, 1 y 1, es 2, puesto que, una vez ordenados los datos: 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 4, el que ocupa la posición central es 2:

 Se toma como mediana
Se toma como mediana  Existen métodos de cálculo más rápidos para datos más númerosos (véase el articulo principal dedicado a este parámetro). Del mismo modo, para valores agrupados en intervalos, se halla el "intervalo mediano" y, dentro de éste, se obtiene un valor concreto por interpolación.
Existen métodos de cálculo más rápidos para datos más númerosos (véase el articulo principal dedicado a este parámetro). Del mismo modo, para valores agrupados en intervalos, se halla el "intervalo mediano" y, dentro de éste, se obtiene un valor concreto por interpolación.